网易云音乐爬虫示例
下面使用cheetah来获取网易云音乐中的热门评论。
1. 观察网站
打开云音乐网站的分类页(一般都从分类页爬取,如果有的话),http://music.163.com/#/discover/playlist/?cat=%E5%8D%8E%E8%AF%AD ,这里选的是华语类别。这里需注意的是链接的那个#需要去掉,否则获取不到。
从分类页分析到歌单页,再到歌曲详情页,发现只有它的评论是动态渲染的,直接爬取拿不到。继续打开调试器查看请求。
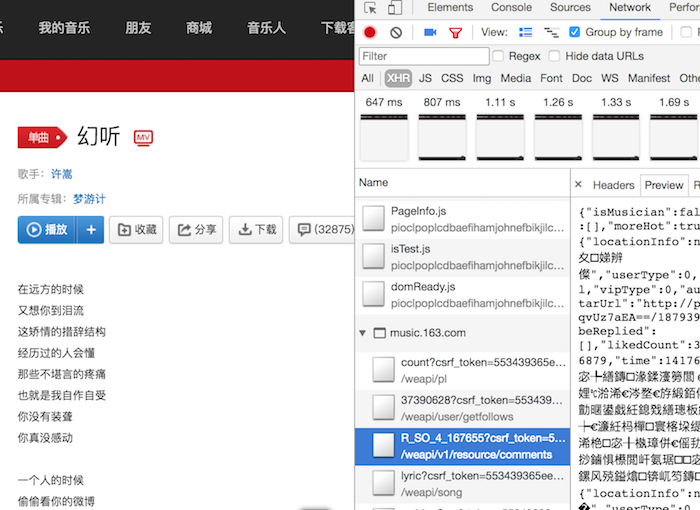
经发现,评论的完整的请求地址为
http://music.163.com/weapi/v1/resource/comments/R_SO_4_167655?csrf_token=
经过分析,该地址的167655为这首歌的id,歌曲id可以简单从歌曲url中获取。csrf_token为用户标识,对爬取无用。其中还有两个参数,params和encSecKey。这两个参数很复杂,网上有解析怎么生成的,不过我直接用浏览器现成的参数就直接可以。
到目前网页的分析工作就完结了。初步定下任务为,评论使用API获取,其他使用网页解析完成。
2. 编写爬虫
创建MusicCrawler实现PageProcessor,并将网页解析的任务完成。
public class MusicCrawler implements PageProcessor {
@Override
public void process(Page page, CheetahResult cheetahResult) {
String url = page.getUrl(); // 获取当前爬取页url
int index = url.lastIndexOf("song?id=");
if (index > -1) { // 若是详情页,解析网页获取结果
Selectable songInfo = page.getHtml().$(".m-lycifo .cnt");
String name = songInfo.$(".tit em").getValue();
String singer = songInfo.$("p").get(0).$("span a").getValue();
String album = songInfo.$("p").get(1).$("a").getValue();
String musicId = url.substring(index + 8).trim();
Map<String, Object> result = new HashMap<>();
result.put("name", name);
result.put("id", musicId);
result.put("singer", singer);
result.put("album", album);
cheetahResult.putResult(result); //储存爬取结果
cheetahResult.setStartJsonAPI(true); // 本次爬取允许JSON API
} else { //否则,可能是歌单页或是分类页
Selectable discover = page.getHtml().$("#m-disc-pl-c");
//歌单类型
List<String> typeUrls = discover.$("#cateListBox > .bd .f-cb").get(0).getLinks();
cheetahResult.addWaitRequest(typeUrls); //储存待爬结果
//歌单
List<String> playUrls = discover.getLinks("#m-pl-container li > div.u-cover");
cheetahResult.addWaitRequest(playUrls); //储存待爬结果
//下一页
List<String> nextUrl = discover.getLinks("#m-pl-pager .u-page");
if (nextUrl.size() > 1) {
cheetahResult.addWaitRequest(nextUrl.get(nextUrl.size() - 1));
}
Selectable playInfo = page.getHtml().$("#song-list-pre-cache ul");
List<String> songUrls = playInfo.getLinks();
cheetahResult.addWaitRequest(songUrls); //储存待爬结果
cheetahResult.setSkip(true); //过滤本次结果,即本地爬取无结果(不是详情页)
}
}
@Override
public SiteConfig setAndGetSiteConfig() {
return null;
}
@Override
public void processJSON(JsonDataResult jsonData, CheetahResult cheetahResult) {
}
@Override
public Request updateJSONConfig(CheetahResult cheetahResult, SiteConfig siteConfig) {
return null;
}
}
解析网页的过程分为了详情页和非详情页。只有详情页才有歌曲信息及评论,其他页都是为更多收集详情页的。
这里主要解析下
cheetahResult.setStartJsonAPI(true); // 本次爬取允许JSON API
前面提过,在一次爬取中的顺序为 process --> updateJSONConfig --> processJSON
这样设计的考虑是,在一次爬取中,可能单纯的解析操作(precess()操作)不能完成整个结果。就如本例,process()只获取到了歌曲的曲名、歌手、专辑等信息,而得不到这首歌的评论信息。这样将processJSON放在process后面,两个函数共用一个CheetahResult 实例,就可将评论添加到对应歌曲后面。
事实上,CheetahResult本身代表一个列表,如果想让`process`和`processJson`合并成一个结果,则都储存到第一个元素即可,否则储存在不同元素。
API JSON的设置
首先是updateJSONConfig(),前面已经提过,在本例中它的任务是替换歌曲的id值,同时构建一个post请求。
@Override
public Request updateJSONConfig(CheetahResult cheetahResult, SiteConfig siteConfig) {
if (cheetahResult == null) {
return null;
}
//替换json url中的歌曲id
String url = siteConfig.getJsonAPIUrl();
Map<String, Object> music = cheetahResult.getResults().get(0);
String newUrl = "";
if (music != null) {
String oldStr = url.substring(url.lastIndexOf("R_SO_4_") + 7, url.lastIndexOf("?"));
String newStr = (String) music.get("id");
newUrl = url.replace(oldStr, newStr);
}
//构建post请求参数
Map<String, String> paramMap = new HashMap<>();
paramMap.put("params", "2XrYzouNKhZ/ewhVWpTNvNd5kpXAf/QR5moeaTShm0ch2QK/96FpuE2SlEj5BcmeNSvfP+m2KKcOB/aGV9nGLiUwXkbzR88sbEs0UIKcAVDXsQ/84gPB1b12gekAp6vQL6vekQP6aXKx9bSMSzBPXchRhz1+ESQwAOmGaQ2YfniEuB9W6hUScyOT16vlujOapKIQKo5CKoM5pqP2JVAIS828fsuGNIf2LA3clcq4/1Y=");
paramMap.put("encSecKey", "7dad56c9971eaa36785ef9ecc956597f184d72bf29de68671d5ac5e188d5dd248cbb20a32ff02a6c5959e750d215c71607067d9c4c50856664b1b07ea280946fb954e6341f9d6af340632c61af71c7d30b7e72ded33a56570345bbc972cc06203587174a003ce9bc390d0c59235e4215f54b4f1640bc87f4857bd9c5f3cbde0b");
return new Request(newUrl, paramMap, RequestMethod.POST);
}
接下来就是处理API获取到的数据
@Override
public void processJSON(JsonDataResult jsonData, CheetahResult cheetahResult) {
List<MusicContent> lists = new ArrayList<>();
Map<String, Object> commentData = jsonData.parseMap();
int commentNum = (Integer) commentData.get("total");
List<Map<String, Object>> listData = (List<Map<String, Object>>) commentData.get("hotComments");
listData.forEach(map -> {
Map<String, String> user = (Map<String, String>) map.get("user");
String nickName = user.get("nickname");
int likeNum = (Integer) map.get("likedCount");
String content = (String) map.get("content");
MusicContent musicContent = new MusicContent(nickName, likeNum, content);
lists.add(musicContent);
});
// 设置评论及评论数
cheetahResult.putField("hotComments", lists);
cheetahResult.putField("commentNum", commentNum);
}
MusicContent类为爬虫的内部类,主要为封装评论。其他设置参数、运行方法就不贴了。读者可去 cheetah-music163
查看源码。
看一下爬取的数据吧
